
Lean Data Engineering with Dagster and DuckDB
A simple pattern for aggregating the data you already have


This post was inspired by the work that Jacob Matson, Pete Fein and I have done helping companies make use of their data lakes.
If you’d rather read the code, you can find it all in Github: Lean Data Engineering.
But make sure to check out the Implementing This Pattern in the Real World section before giving it a go.
Data lakes are nice because you can throw anything you want in there and move on. This is also why they cause a lot of trouble.
But, we like quick wins. We also like a short time-to-value. So, we’re going to cover a quick-ish pattern for taking what’s in your data lake and making it useful. Limited fancy tech. Limited infrastructure.
Just python, SQL and a couple tools you may have already heard of.
We’re talking lean data engineering.
There are plenty of different - and difficult - ways to get data from one place to another. But, we’re keeping this simple.
Believe it or not, Dagster, DuckDB and a warehouse of choice (we’re using Snowflake) will take you very far.
AWS and GCP have made it especially easy to create systems designed for high-volume data. In the time it takes to read this post, you could launch your streaming pipelines with AWS Kinesis or GCP PubSub. And landing that event stream in S3 or GCS is trivial.
But, it’s only half the battle.
The last mile - bringing that data into your data warehouse and actually using it - is the real challenge.
Data lakes are convenient, but they reframe traditional data engineering challenges. Technical projects always have some governance and cost components. Within the changing context of a data lake, though, they can quickly become challenges.
They present a set of data engineering problems not found in traditional pipelines. They change the narrative.
There is no friendly package of data + compute. Instead, it becomes ““here is all the data; provide your own compute”.
It’s common to see companies dumping data into their data lake, ingesting it into their warehouse, and processing it repeatedly. It’s a classic trap: a system that is easy to create and hard to maintain.
The Data team might use the data appropriately, but this system leaves your Analytics Engineers, Data Analysts and Data Scientists heading towards a slippery slope. The opportunity to deploy needless dbt models won’t go away. And with that comes ever growing cloud bills. Let’s not forget that you’ve also created a security risk.
PII and other sensitive information will land in your warehouse even when you don’t want it to. It’s one unfortunate side effect of this design.
We’ve all seen it happen.
Even the most cost-conscious teams slip up from time to time.
But we can side-step these issues by returning to an ETL pattern of old. By applying aggregations to our data lake and pushing that data to our warehouse.
And with some specific design patterns, we can build a lean pipeline that fits our current infrastructure.
Plus, we’ll get the data where it needs to be faster and cheaper.
Data Lake + Dagster + DuckDB
There are plenty of vendors who will copy your data lake into your warehouse for a fee. But, we’re not heading down that path. We’re keeping it lean.
You’ll hear a lot of data engineers say to “push it down to the database”, meaning let the DB do the heavy lifting. We’re going to do something similar, but with lighter weight tooling.
We can’t aggregate data directly in the data lake, because we don’t have access to a compute engine.
We don’t want to push the aggregations into Snowflake. That requires we copy everything to Snowflake first, and would be far too costly.
Instead, we’re going to aggregate partitions of data in-process using DuckDB, and dump that to a location accessible by Snowflake.
Anything downstream of that (dbt models, BI reports, etc) are derived from our aggregated data. We’re using our pipeline to perform work we’d be doing anyway.
In theory, you could forgo dbt altogether and treat DuckDB like a data modeling layer, but might be going too far. We still want some separation of concern between data available for use and data ready for consumption (reporting).
We can break our path forward into a few steps:
Pre-processing and Aggregation
Staging and Loading
Reporting and Presentation
We’re going to use Dagster to execute the first 2 steps above. If we opt for layering some lightweight dbt models on top of our data, we can orchestrate that work with Daster, too. But, the method you choose for that section of the pipeline doesn’t matter too much.
We’re already in a good place with data capture - the Engineering team is dumping an event stream into s3. We don’t need to rely on Webhooks from vendor systems, and we’re capturing more data per event than we will use for analytics purposes. With Kinesis, a new file lands in s3 approximately every 15 minutes. A typical payload looks like this:
{
"a_unique_identifier": 1234,
"another_id": "xyz-abc",
"event_type": "signup",
"occurred_at": "2024-03-01T15:00:00.141626",
"source": "data-producer-app",
"raw": {"some": "nested", "json": "data"}
}The files are timestamp partitioned JSON blobs, and there are a lot of them.
But, before we do anything we need to handle two important requirements:
Granularity at a daily grain
Removing PII
Daily granularity is easy enough - we need to run this pipeline at least once a day, and aggregate our output data on at least a per-day basis.
We can fine-tune our controls of PII data as it’s getting processed by DuckDB. A vendored solution would be too costly, especially one that requires this level of configuration.
In years past, you might have opted for Pandas, or some generic CSV processing. But we can minimize a lot of boilerplate code by opting for DuckDB. This also helps us reduce our in-process memory footprint (more on this later).
And, this whole thing is ephemeral - we don’t need to persist our DuckDB instance. We don’t need to maintain state in the pipeline, so we can more easily scale horizontally.
That also means we can re-run jobs with ease.
Our pipeline needs to read and write to s3, make it easy to convert one file format to another, and have a friendly API. DuckDB handles all these requirements with some readily available tooling.
We’re primarily interacting with it via SQL, and it will work with limited domain knowledge. Not to mention we can drop it into Dagster without having to explicitly integrate the two tools.
From there, we produce some parquet files and drop them into an s3 bucket. We wrap it up by having Dagster trigger a load from s3.
This might sound a bit abstract, but it’s conceptually pretty simple. There are a few moving pieces though, so let's look at some code.
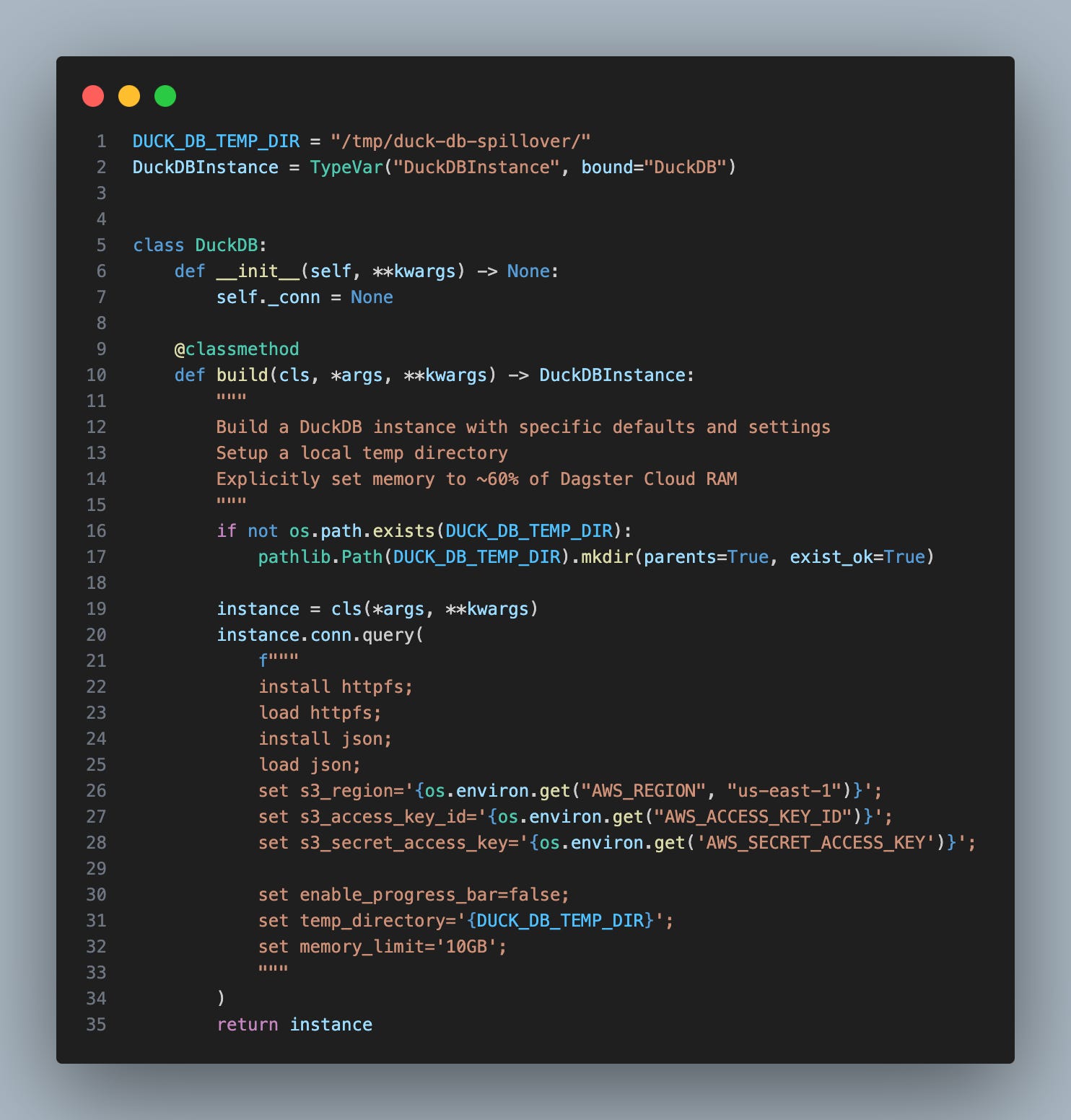
DuckDB.build()
DuckDB is doing the majority of the work in this pipeline. Since Dagster is python based, we’re going to package up our DuckDB interface as a python object, as well. Dagster provides a native integration with DuckDB by way of Resources, but we don’t need that here.
Our class has a .build() method that spits out a DuckDB instance loaded with a specific configuration.
Now we can read json, interact with s3, and handle memory spillage predictably.
Incremental Processing with Partitions
Since our data lake will be growing over time, we need to logically partition our source data. This is especially important given our memory constraints.
We don’t have access to any metadata indicating the size of the file we’re about to ingest. We don’t control the data producing system. And since we’re processing gzipped CSVs, we could have a wide range of compressed files.
Incrementally processing our data at specific intervals is the easiest path forward. And it allows enough flexibility to tweak things as needed.
We can use Dagster’s Multipart Partitions to manage the partition keys we’ll use to filter, parse and process only a subset of files at a time. This is the basis for our incremental processing.

We’re processing events from multiple producers. So, we’re factoring time and origin into our partitions.
We’re going to use this definition in a few places so we’re only ever handling a subset of data at a time. We have some helper functions and utilities to make filtering the s3 files easier, but they are not that interesting.
Within Dagster, two functions make up the vast majority of the pipeline so far - finding some files in s3 and handing them to DuckDB.
Those functions are tidy, too. They find files we need to process and execute queries against them.
In one case, we cast JSON to Parquet. In another, we do a rollup.

With the hive partitioning and file type conversion, executing a daily rollup would be much more difficult.
By converting the JSON data to Parquet, we can now just point DuckDB to those files, aggregate them, and ship them off to another location in s3.
And, it can happen without having to give DuckDB a predefined schema.

Ship it off to Snowflake
We’re 80% of the way.
We already did most of the heavy lifting in-transit with DuckDB and Dagster. The final step is loading our pre-processed data into Snowflake.
We want to keep things relatively streamlined in Dagster and in Snowflake, so we’re defaulting to CREATE IF NOT EXISTS for a Parquet file format, Rollup Stage and Rollup Table.
Dagster’s Resource pattern makes it easy to inject interfaces into your databases and cloud storage into your job context.
Instead of managing all of our CREATE IF NOT EXISTS statements with inline sql, we’re going to set up a ConfigurableResource as a “public interface” into our data warehouse. This is how we’ll execute the commands we need to take the staged Parquet files, and ensure they land where we want in Snowflake.

The last remaining piece? Copy our staged data into the rollup table using our SnowflakeResource, and we’re done.
From here, anyone with a connection to Snowflake can make use of our newly minted rollups.
And backfills are easy, too, thanks to the partitions.
Quick Aside: If Money Were No Object
If we weren’t considering cost, Snowflake and BigQuery offer plenty of options for getting your data from where it lives to where you want it.
Snowflake Dynamic Tables and Tasks work well for transferring files from s3 into your warehouse for additional processing. In BigQuery, the Data Transfer Service provides similar tooling.
But, you’re still incurring storage and processing cost at multiple points. You’d still be copying the “raw” data in your warehouse where you’d have to do more transformation. Adding dbt into this mix quickly takes you from “data-driven” to “cost-center”.
Implementing This Pattern in the Real World
Examples and walkthroughs are nice, but in the real world, there are always challenges. Here are some “gotchas” that came up when implementing this pattern for a real-world Marketing SaaS.
Your DuckDB configuration matters, and it depends on the platform you’re using
More specifically, your DuckDB Memory Limit and Temp Directory configurations matter. If you’re running this pipeline on an EC2 instance with comically large RAM, you won’t have to worry too much about memory. If you’re running it on a small instance, or through Dagster Cloud, you will have memory limits.
And those memory limits are important.
Since our data is loaded as gzipped JSON and written as Parquet, we don’t know the initial memory requirement until the filetype changes. The collection of gzipped files may be small or large. Because of this, you need to be able to spill to your local disk since your RAM will not be enough for in-memory processing. We settled on 10GB of RAM since Dagster Cloud defaults to 16GBs.
On high-volume days, we saw activity skyrocket. As a result, we needed to plan for the edge cases.
Just use Parquet
Speaking of JSON and Parquet, DuckDB will cooperate much better with Parquet files than Gzipped JSON. No surprise that an in-memory database will work better on files with attached metadata, so if you have the opportunity to update your Kinesis pipeline to write your event batches as Parquet, you should do it.
Preserve a lower level grain in the pipeline when you can
Any experienced data engineer has been here. The requirements expect daily aggregations. But if you can process things on an hourly basis with minimal cost or performance impact, it’s probably worth doing so from the start.
By presenting daily aggregations to the user, but keeping hourly rollups under the hood, you keep things flexible. You can change the granularity of reporting in the future, but you don't need to make major changes to do it.
Build once, share twice
We dump this data Snowflake in this scenario, but there’s no reason to stop there. Other systems (including the production application!) can use the aggregates that land in s3. Making use of the data you have does not just mean it gets shared via BI report.
Backfill configuration is trivial, but execution is not
I also happened to crash our Dagster Cloud deployment because of backfills. Pair intermittent high-volume periods with a large number of backfill jobs, and the result is poor UI performance. Unfortunately, I caused issues for other Dagster customers, too.
Simply put, we were creating so many "JobRun" objects that the UI failed to load. And, other Dagster Cloud customers were seeing degraded performance as a result.
Dagster was quick to solve that issue for everyone. Props for moving fast.
But, this brings up 2 changes I'd make next time.
First, change the way DuckDB aggregates a single batch of data. Rather than running 1 job per hour, we could run one job per day , and write local Parquet files partitioned by hour. You maintain the same granularity, but significantly reduce the number of jobs tied to your Dagster instance.
Second, use a hybrid deployment rather than a strictly serverless design. At least this way, we could manage the RAM and CPU settings ourselves.
If you have thoughts or comments, give me a shout on Twitter or LinkedIn.
Great article